
The magic of LUTs to implement random logic in an FPGA.
2024.05.27 : I’m Kevin Hubbard, BSEE with 40+ years experience designing digital logic, 30+ of those years actually getting paid for designing ASICs and FPGAs for really cool shit in various electronics industries. In Part-1 of this series ( which starts here ) I described FPGAs as this magic array of D Flip-Flops that could be interconnected with each other via PIPs ( programmable interconnect points ).
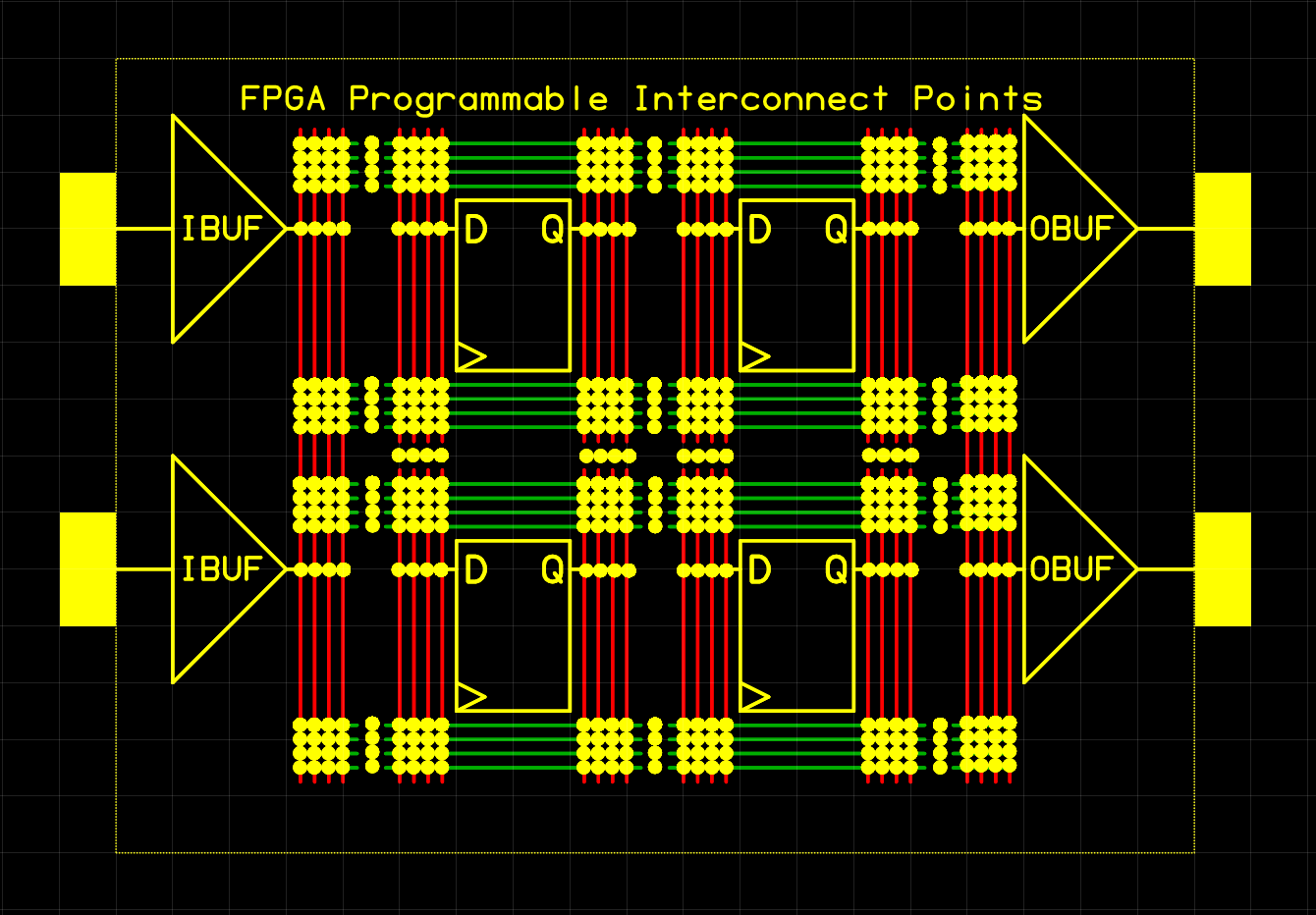
This was an oversimplification of course. An array of D Flip-Flops by themselves just isn’t that useful. You can implement a shift-register ( which I did ) and that’s about it. Sure – add a Q-not and you’ll get a Div-2 clock divider. There must be more to FPGAs and there is – in the magical LUT ( Look Up Table ).
A LUT is a very small SRAM. In this 1st example, it has 2 address lines (Inputs) and 1 data line (Output). By configuring the 4 address regions of a 2-input LUT differently, the basic Boolean logic gates may then be implemented.


Now just stick this simple LUT in front of each Flip-Flop of an FPGA and some very interesting logic designs can be implemented. Note that Synthesis and Mapping takes care of configuring these LUT memories. Once FPGA configuration has completed, each LUT can be thought of as a fixed Boolean logic gate in function.

Note that actual LUTs in commercial FPGAs are slightly larger, with a few more inputs and outputs. This allows for a single LUT to implement the commonly used circuit of a Full-Adder necessary for creating a binary counter. LUTs can be cascaded into multiple levels of logic. Each level, along with routing, adds propagation delay though. If you have a 200 MHz clock, it’s easy to consume the entire 5 ns clock period between two flip-flops with routing and just a few LUTs between them.

Seems appropriate to close out Part-4 by inferring a 4-bit Full-Adder in Verilog and VHDL and flash the original 4-LEDs in a binary counter fashion. Here is the entire design in Verilog RTL ( including the 1 Hz clock divider ).

and to be completely language neutral, the same RTL design but in VHDL:

And finally, the Verilog netlist exported out of Vivado using the command “write_verilog -force ${design_name}_netlist.v“. The 1 Hz circuit is again removed to keep things clear and simple. The design again has an IBUF and BUFG for the clock tree, 4 OBUFs for driving the external LEDs, 4 Flip-Flops ( FDRE ) and now 4 LUTs. Note that the D(0) LUT has 1 input and 1 output while the D(3) LUT has 4 inputs and 1 output – as expected – to implement a 4bit binary adder.

I don’t usually use the Vivado GUI, but I will briefly to close out this Part-4 to illustrate what the fully placed and routed 4-bit binary counter looks like. To do this, I’ll need to add the “write_checkpoint” command to my original “go.tcl” script just after the place and route commands:
[ go.tcl ]
place_design
route_design
write_checkpoint -force routed_design
This will create a file called “routed_design.dcp” that the GUI can then open. From the command line, type “vivado” and then click [ File ], [ Checkpoint ], [ Open ] and selected “routed_design.dcp”.
Once the GUI has loaded the design, you can select the “Leaf Cells” on the left and they will become white highlighted within the floorplan of the FPGA silicon die. The “Leaf Cells” are the gate primitives within the FPGA – the Flip-Flops, LUTs, IO Buffers etc.

Since this FPGA design is mostly empty – I have to Zoom-in a LOT to shows the 4-bit counter design details. Here is a Zoom-in on a single AMD/Xilinx 7-Series “Slice” which contains all 4 flip-flops of the binary counter design. Gone are the simple CLB ( Configurable Logic Block ) days of a 4-input LUT connected to a single flip-flop. You know how an Atom has Protons, Neutrons and Electrons? An AMD/Xilinx 7-Series “Slice” is made up of 8 flip-flops, 4 either 6-input or 5-input LUTs, 3 general purpose 2:1 muxes and a single carry block with some (4) dedicated XORs and 2:1 muxes.

Zoom in a bit more for some more LUT details. What’s fascinating about this, is that I’ve been designing with 7-series parts for a decade now – and I’ve never bothered to know these precise details. That’s the magic of RTL high-level abstraction for FPGA design. I just need to know that there are LUTs between Flops. Having this high-level architecture knowledge prevents me from say inferring a 128bit counter at 300 MHz. The details on how many LUTs and Flops and muxes in a Slice though, that doesn’t influence my day to day decision making at all.

The floorplanner tool by default shows routes ( nets ) in a ratsnest representation. The actual routing is Manhattan-Routing with lots of PIP interconnects along the way.

The routing within a Slice is pretty boring, but highlighting the routing between the D-Flop Q output and the OBUF for driving the LED reveals 14 PIPs spanning a long distance.

Click on the “Routing Resources” button and it switches to a Manhattan-Route view. Funny little circle path it takes towards the OBUF isn’t it? The router had its reasons I’m sure. The great thing is, I don’t have to know the reason why. I just need to know if the route made timing or not.

The important lesson here is that FPGAs have non-infinite metal routing features and routing congestion is often to blame for missing otherwise reasonable timing closure. It is counterintuitive, but I have “saved” many designs in the past by running buses at 4x their necessary rate ( say 400 MHz instead of 100 MHz ) and using this speed advantage to reduce the bus routing width 4x ( say 40 down to 10 ). It’s called time-multiplexing a bus. It’s a 150 year old electrical engineering practice and it’s a critical tool even today for a digital chip designer’s toolbox.
I took this to the extreme with my OSH Sump3 RLE ILA ( here on GitHub ) by having each RLE compression Pod interconnect with the master core controller using only two nets, a MISO+MOSI pair. It’s a distributed logic analyzer requiring minimal global routing resources. My #1 goal with designing Sump3 was to make an ILA that could be added to a “full-up” design and not break the design in the process.
That’s it for Part-4. In Part-5 I show how to simulate the 4-bit counter using ModelSim. For very simple designs ( like the one above ), I just “simulate” the design in my head. Modern FPGAs can have billions of transistors in them though. Once I get beyond a few dozen flip-flops, it’s time to bring in an RTL simulator like Mentor Graphic’s ModelSim.
Since I don’t have Xilinx primitives compiled for my Intel / Altera ModelSim install, I will split the design into a top-level containing Xilinx primitives and a “core” level with inferable RTL for simulation. Excluding IP cores like FIFO, it is customary to separate clock tree and I/O buffers apart from RTL.
EOF























